I finally got around to replace OpenWrt CC with LEDE 17.01.00, and consequently the first time to use SQM with cake. First on my home router, a WD My Net N750. Other routers will follow.
qdisc is cake, script is piece_of_cake. At first, I went with the recommendations as documented: 90% of upstream/downstream for ingress/egress and 44 on the packet overhead (I'm on an ADSL2+ line), and all of that on the PPPoE interface. And everything went as expected, the line was considerably slower than without SQM, but bufferbloat was well-controlled and the line felt a lot more responsive under load.
Then I started to fiddle around with the settings, out of pure curiosity and maybe to squeeze it so I would get peak speeds close to a QoS-less setup. And long story short, I ended up with a completely different set of values.
I now have
SQM running on the ethernet interface the modem is connected to (eth0.2 in my instance) instead of pppoe-wan
ingress/egress set to exactly 100% of the modem synchronization values (it would even work with a value larger than the sync values, but I left it at that since that didn't seem to make a whole lot of sense to me and I don't want to "tease" and try to be smarter than the algorithm)
overhead set to 23 instead of 44 (any lower than 23 and bufferbloat would skyrocket), that one I found by trial and error
With this, I still get consistent As on the dslreports.com speed/bufferbloat test (I never got an A+ anyway). The line is snappy even under full load, and overall speeds are comparable to what I had without SQM.
My question now is, how is it that my "optimum" values differ so much from the recommendation? I can somewhat see the ingress/egress values, but especially the overhead puzzles me since surely that would have a technical reason and not an "experimental" background.
So this is slightly dangerous as sqm will now see the pppoe LCP packets and hence will also be able to drop those. Since sqm does not special case those if you happen to drop like 5 in a row your pppoe link will go down. Before cake (which will drill down into the packets headers simply "piercing" through ppp headers in its search for IP/IPv6 headers) sqm could not look past the pppoe header in the packets and hence could not diffeentiate priority based on DSCP markings (and HTB+fq_codel still can not, but cake can). Since you are using cake this second issue dos not apply to you, but the first still could cause issues (that said, LCP packets are typically once per second and hence should profit from the sparse flow boost that cake ad fq_codel give to survive).
So on egress, with the correct overhead and link layer accounting I have repeatedly seen rock-solid low-bufferbloat shapers on a number of technologies (DOCSIS, ADSL2+, VDSL2). But on ingress I would not be so sure, ingress shaping is approximate in nature. Have a look at flent (https://github.com/tohojo/flent/tree/master/flent) and do a rrul_cs8 test against a potent server, or use the dslreports speedtest with 32 streams in each direction, to emulate what happens when lots of independently controlled streams hit your ingress... (this is like a poor man's substitute for heavy torrent traffc....)
Good for you, it is actually recommended to look at the real overhead (for example using https://github.com/moeller0/ATM_overhead_detector). The recommendation of 44 bytes comes from the fact that this for some time was close to the typical situation and also close to the worst case, so for people with insufficient time to measure the overhead this recommendation should help to end up with a functional bufferbloat reduction.
That said, 23 looks rather odd, please note that on pppoe-wan you will need to specify 8 bytes more for the same effective overhead, as on pppoe-wan the kernel does not see or account for the 8 byte pppoe header. The closest to your 23 would be the 24 Bytes expected for PPPoE, VC/Mux RFC-2684; Protocol (bytes): PPP (2), PPPoE (6), Ethernet Header (14), ATM pad (2), ATM AAL5 SAR (8), of these 32 bytes the 8 for PPP/PPPoE live inside the MTU so from eth0.2's view you would only need to account for 32-8 = 24 bytes. Could you please let us know which ISP you are customer of?
Maybe you could also post the output of:
cat /etc/config/sqm
tc -s qdisc
Thanks in advance.
As far as I can tell this is pretty much as expected, the shaper percentage is a policy question and depends on which latency under load increase (bufferbloat) versus bandwidth sacrifice trade-off a user is comfortable with. Also with link layer accounting set to to ATM you already have an effective reduction of your useable bandwidth by 9%, the old 85-90% recommendations mostly came from a time when precise ATM link layer accounting was not an option....
The overhead again is also not that puzzling in that the recommendation is puroposefully on the safe side, the actual value of 23 however seems odd (but hey this might be true). If you have time to waste and use the ATM_overhead_detector, I would be delighted if you could post your results here (the numeric output)...
Assuming your ISP actually uses PPPoE, yes ;), But again the issue is less important with cake's ability to get IP addresses and TCP/UDP port numbers in spite of PPPoE headers...
Alright, I switched it back to pppoe-wan, and it doesn't seem to make any significant difference. Thanks for the advice.
With 32 concurrent streams in the dslreports test, ingress is fine, bufferbloat goes up, but it will stay usable (varying wildly between 20ms and 200ms, even the worse cases are certainly still better than without SQM). And with a few less streams, everything remains well-controlled. TBQH, that's good enough for me (I don't do any torrenting nowadays and I feel even with heavy browsing I don't hit those limits).
What worries me a little bit is that 32 concurrent egress streams bring the test to a halt at the end, transfer speeds nosedive, ending in an error message about "too much upstream buffering" -- even when I set egress considerably lower than my sync, even when I test with only 16 streams, it doesn't make any difference, it results in an error.
That would be Germany's Easybell, by extension Ecotel, on a DSL line provided by Telefonica.
As for the ATM_overhead_detector result, if and when I find the time to waste a few hours, sure. In the meantime I switched to 24 as per your (well-argumented) recommendation, and again it doesn't seem to make any noticeable difference. (And yes, being a programmer, I found an uneven number like 23 slightly odd too. )
Okay, if 200ms is not a problem for you, it seems you can reclaim a significant portion of your ingress bandwidth.
With at best probably 1024 Kbps upstream each packet will block the line for (53328)/(10241000) = 0.01325 seconds, so if 32 of those pile up this adds up to 32 * (53328)/(10241000) = 0.424 seconds, which might explain the problem partly. I guess with that kind of of upstream maybe 8 streams would be better. But my point was exactly that, testing with less than ideal traffic often helps to better understand the tradeoffs one selected...
And this is fine, in the end it is a policy decision one needs to make, the nice thing about cake and fq_codel is that it allows us to make informed decisions.
Ah, okay that means classic ADSL2+ @AnnexB, no idea what encapsulation they use on those lines...
Yeah, it doesn't seem to make any difference which egress bandwidth I set in SQM or whether I have it running at all. Anything more than a few (constant) upstreams completely weigh down the line, and 16+ streams grind it to a total halt. 仕様がない, it can't be helped, it seems to be a problem that comes with the very limited upstream bandwidth. And it's certainly a fringe case for me, as long as I'm not doing a huge number of large upstreams I should be just as fine as I have always been before.
Thanks for all your advice, it is well appreciated.
Okay, if the issue only arises with the speedtest, ignoring it seems fine, but even a slow upstream should work to some degree, could you maybe post the ooutput of:
cat /etc/config/sqm
tc -s qdisc
please?
So from the pastebin page it is clear that you are using the tc_stab method for link layer accounting instead of cake's own inbuilt one. That in turn means that with your eth0.2 tests the effective overhead was not 23/24 but rather 23+14/24+14, or 32Bytes. Also you are running pretty much with the default cake options. For comparison here is my /etc/config/sqm:
config queue
option debug_logging '0'
option verbosity '5'
option enabled '1'
option interface 'pppoe-wan'
option download '46246'
option upload '9545'
option linklayer 'ethernet'
option overhead '34'
option linklayer_advanced '1'
option tcMTU '2047'
option tcTSIZE '128'
option tcMPU '64'
option linklayer_adaptation_mechanism 'default'
option qdisc 'cake'
option script 'layer_cake.qos'
option qdisc_advanced '1'
option ingress_ecn 'ECN'
option egress_ecn 'NOECN'
option qdisc_really_really_advanced '1'
option iqdisc_opts 'nat dual-dsthost'
option eqdisc_opts 'nat dual-srchost'
option squash_dscp '0'
option squash_ingress '0'
This is for a VDSL2 link with 1526 frames length, since the shaper is instantiated on pppoe-wan I need to add 26+8 = 34 bytes of overhead, since packets on pppoe-wan will not have the PPPoE header added when seen by the qdisc.
I would recommend to try to add:
option qdisc_advanced '1'
option qdisc_really_really_advanced '1'
option iqdisc_opts 'nat dual-dsthost'
option eqdisc_opts 'nat dual-srchost'
to your /etc/config/sqm as these settings will instruct cake to act in a per-internal-IP-address fair way (in a first pass and still per-flow-fair "inside" each internal IP category). Unless you are only using one device in your network, that might actually be a nice improvement.
It is the "overhead 34 via-ethernet" part that is missing in your output that tells me that you need to manually take the 14 bytes the kernel might or might not add into account (also the max_len 1749 tells me you are using tc_stab, as 1749/53 = 33 this means that that packet plus overhead was encapsulated into 33 ATM cells of 53 bytes each; in my example with cake being in charge of the linklayer adjustements and overhead accounting max_len 1492 shows the packet size before cake's internal estimations, and 1492 = 1500 - 8 which illustrates that on pppoe-wan interfaces the pppoe header is not yet added). Comparing the max_len between your eth0.2 shaper 1749/53 = 33 ATM cells and the pppoe-wan shaper 1696/53 = 32 ATM cells indicates that you really should use overhead 32 on the pppo-wan interface.
BTW, it looks like your still have cake running on both eth0.2 and pppoe-wan, according to your description both are using the same physical interface, so maybe you could re-do your pppoe-wan tests with that other cake instance disabled first? I have a hunch that things might work a bit nicer with only one shaper instance per direction.
[quote="moeller0, post:10, topic:2578"]
So from the pastebin page it is clear that you are using the tc_stab method for link layer accounting instead of cake's own inbuilt one.[/quote]
Uhm ... okay. I never set anything to tc_stab, and I can't see any configuration option for it either. Where/how/what can/should I set that to cake's own?
Edit: Found it, hidden in the "advanced" section that I never touched before.
And yes, pretty much everything is default. I pretty much installed SQM, set qdisc to cake, script to piece_of_cake.qos and turned it on. The only things I varied until now are the interface it latches on to, and the bandwidth/overhead numbers.
I will try your options, but yeah, at home there's almost exclusively one machine running (just the occasional webradio and smartphone, but they don't do all that much). I'll definitely keep those options in mind for when I switch to LEDE and SQM in my SoHo environment, it makes a lot of sense there (there we are on a bigger line, though).
As you can see from the config file, I only have that one instance on pppoe-wan configured. However, I didn't reboot between switching back from eth0.2 to pppoe-wan. I should do that, shouldn't I?
Edit: Found that, too. It seems SQM removes an instance when you disable it, but not when you switch it to another interface without disabling it first. I believe that could even classify as a bug.
So this thread may basically be useless. After the second unwanted instance on eth0.2 is gone, SQM pretty much behaved like it is described in the manual. It now needs around 5% of down- and upstream to work its magic. And the overhead at 32 seems to fit better, at least with the "cake" adaption mechanism.
So it seems I moved myself into some sort of heisenstate with those eth0.2 shenanigans. Thanks for all your advice.
You know what's quite frustrating, though? SQM is pushed as a huge advancement of LEDE over OpenWrt, and rightfully so. But it is basically a huge black box with lots of strings to pull, and if you pull one just the slightest bit wrong it just doesn't do what you expect it to do. I can't shake the feeling that you might be one of the very few people who actually understands exactly what it does and how to configure it, and we are damn lucky you are approachable and willing to help.
I would not say that, I believe it helped you understanding the issue better and optimizing your configuration. Now, that approach might not scale to well, but it is not useless
Mmmh, the goal of sqm-scripts is to make it simple to get a reasonable shaper going that will mostly do the right thing or at least "no harm". Doing so entails to some degree simplifying things and descriptions. What might be lacking are descriptions of increasing level of detail, but I guess someone would need to write those...
Thanks for the praise, but I am far from understanding the issue, I have been dabbling with this simply long enough to have encountered solutions to a few issues (and I might have picked up some trouble isolation skills along the way).
Not trying to drag this part of the conversation out too long, but yes, to get it going -- i.e., to install it and have it run -- is indeed simple. Anything beyond that is amazingly difficult and quite oblique, and unless you spend a lot of time with mostly nonexistant documentation, you may have to resort to trial and error, and you could still end up with something that behaves in erratic ways like in my example. That might be par for the course with other professional-grade traffic shapers, but simple as in "end-user just wants it to run on the home router" it is most certainly not.
And I feel this will be an ongoing topic, again, now that SQM with Cake is literally the only feature mentioned in the LEDE release notes.
Question, have you read https://lede-project.org/docs/howto/sqm? If you have what are the short comings of that document (besides maybe not being prominently linked to from the luci GUI)? Which questions you have are answered there and which are not? No snark, I really want to know so we can try to improve that page.
I do believe that some of the step learning curve comes from the fact that the issues are reasonably complex and that there is loads of background information that would be helpful to understand things better but that would make the whole description way to long for people to read through....
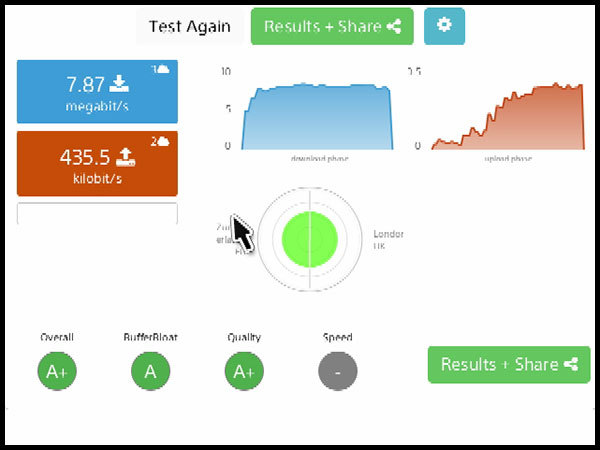
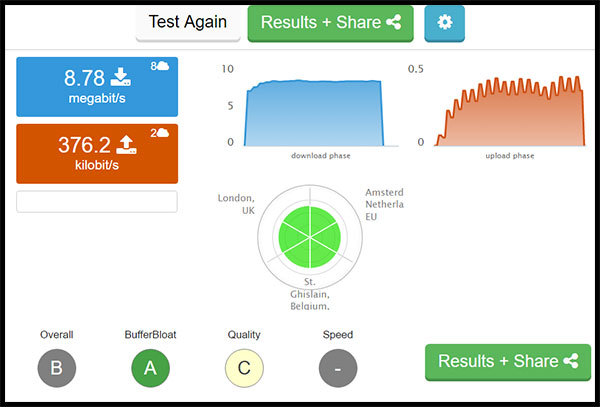
May have to buy a new dongle for my PC (Netgear AC1200) as iPad and PS4 get good results but PC is off a bit which i can only think is down to the dongle
nice thank you. If you press the green Results + Share button you land on a page with more details. If you could post links to that page (you get a unique URL per performed speedtest) that would be even more informative than the images above.
Also note that with your ~430 Kbps uplink you will need to accept around 26ms latency under load increase by serialization delay of a single packet, so latency will always be an issue on your link....
@moeller0
I think if you add ack-filter to both ingress and egress this will help keeping latency good and also will keep download/ upload speed stable.